| Name | Last modified | Size | Description | |
|---|---|---|---|---|
| Parent Directory | - | |||
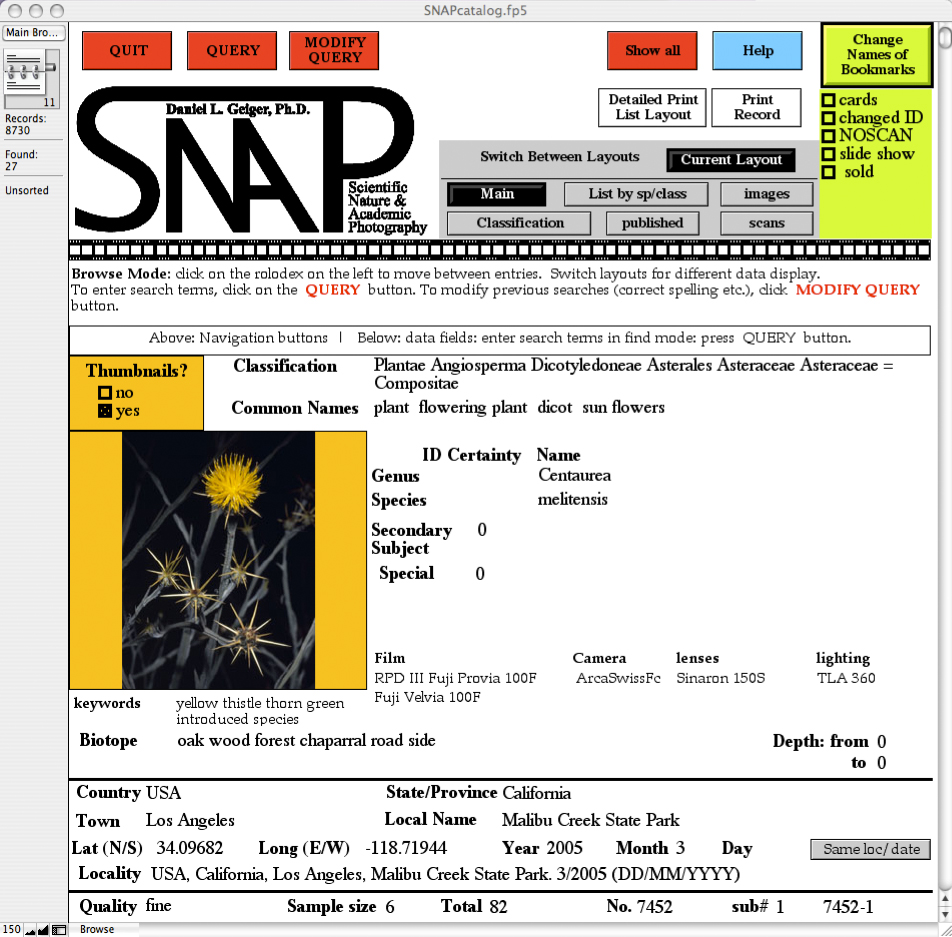
| GeigerFig1.jpg | 2006-03-21 21:29 | 463K | ||
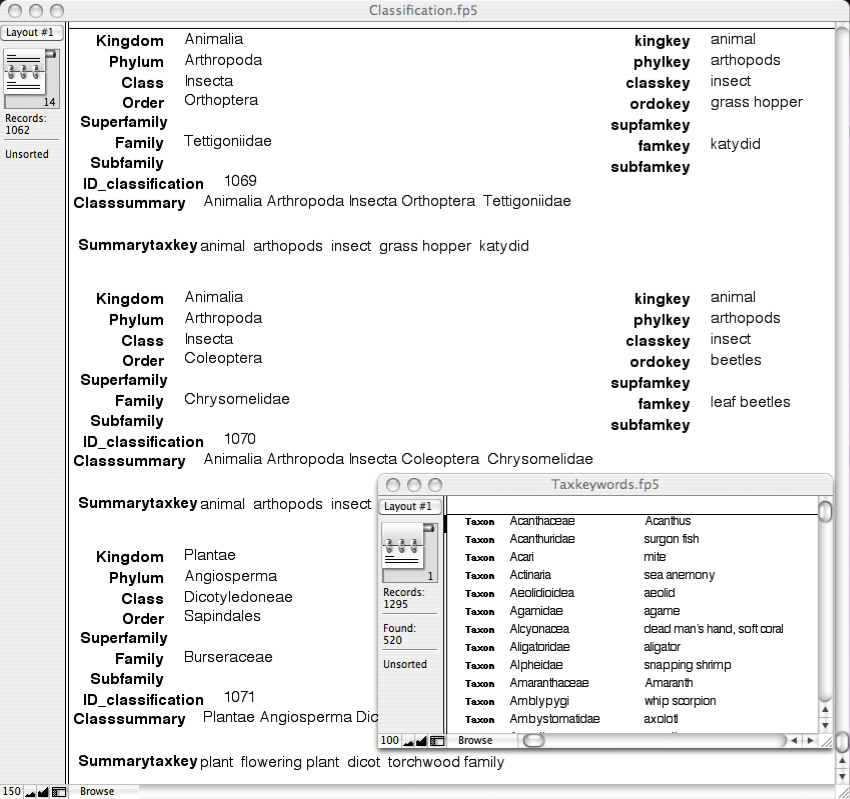
| GeigerFig2.jpg | 2006-12-31 17:59 | 247K | ||
| GeigerFig3.jpg | 2006-03-21 21:54 | 384K | ||
| GeigerFig4.jpg | 2006-03-21 21:40 | 302K | ||
| GeigerFig5.jpg | 2006-03-21 21:53 | 460K | ||
| printfile.jpg | 2006-12-31 18:16 | 139K | ||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}